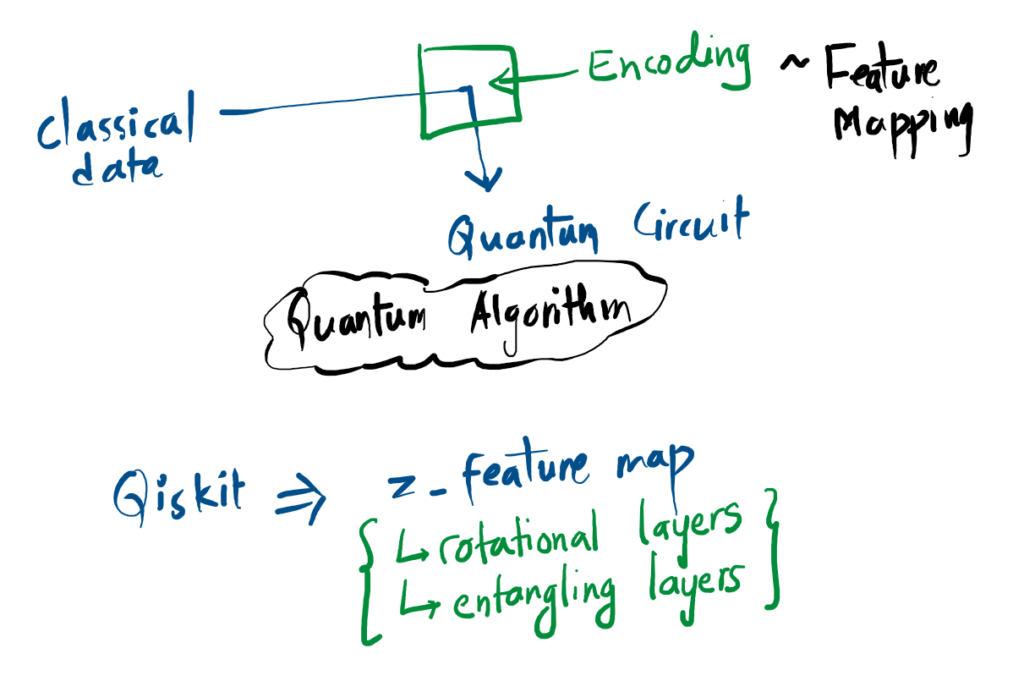
For classical data to be used by quantum circuit, it needs to be encoded which is called data encoding. In qiskit, we can use tools like z_feature_map or zz_feature_map etc. which includes rotation layers and entangling layers.
Normalization is required in quantum machine learning similar to in classical machine learning.
Normalization
Before classical data can be processed by a quantum circuit, it must be mathematically structured to follow the rigid laws of quantum mechanics.
1. The Language of Data
A dataset \( X \) is a collection of \( M \) vectors. We represent an individual vector as \( \vec{x}^{(j)} \), where each contains \( N \) specific features (dimensions).
\( \Phi(\vec{x}) \): The “Feature Map” notation used in general machine learning.
\( U(\vec{x}) \): The “Unitary” notation used in quantum circuits to show that data loading is a physical transformation of the qubit.
2. Normalization: Reshaping the Data
In classical ML, we use Min-Max scaling to keep values between 0 and 1. In the quantum world, normalization is a physical requirement: the total “length” of the quantum state must always be 1.
[0, 1]
Classical Unit Box
= 1
Quantum Unit Sphere
Classical normalization fits data into a flat range; Quantum normalization projects data onto the surface of a high-dimensional sphere.
3. The Unitary Constraint
Quantum mechanics requires the 2-norm (the length) of the state vector \( |\psi\rangle \) to be exactly Unity to ensure measurement probabilities sum to 1:
This constraint dictates how we rescale information:
- Amplitude Encoding: The data vector elements are scaled so their squares sum to 1 (\( |\vec{x}^{(j)}| = 1 \)).
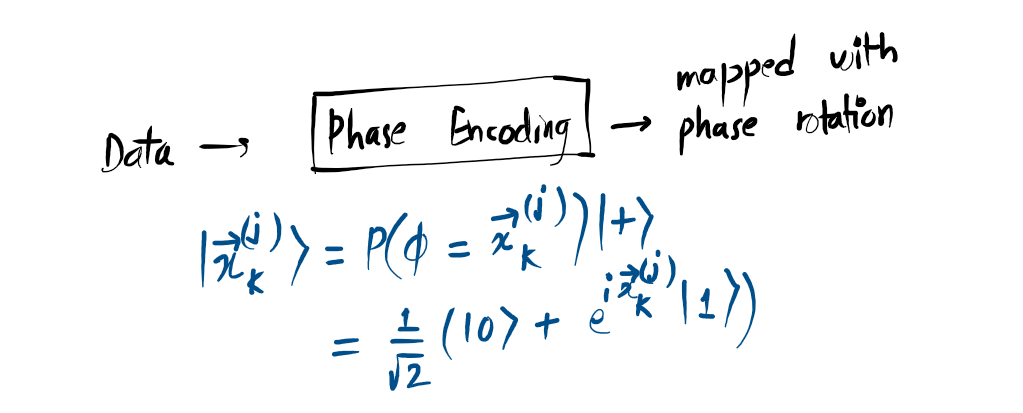
- Phase Encoding: Feature values are rescaled into the range \( (0, 2\pi] \).
There are various types of data encoding such as basis encoding, amplitude encoding, etc.
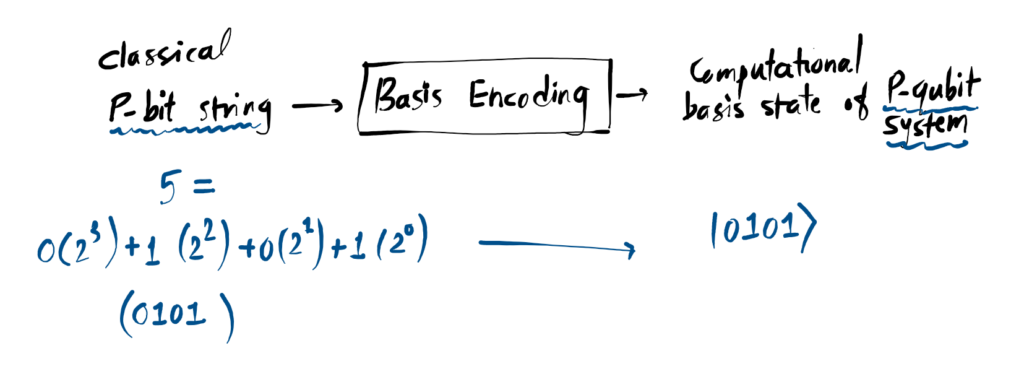
Basis Encoding:
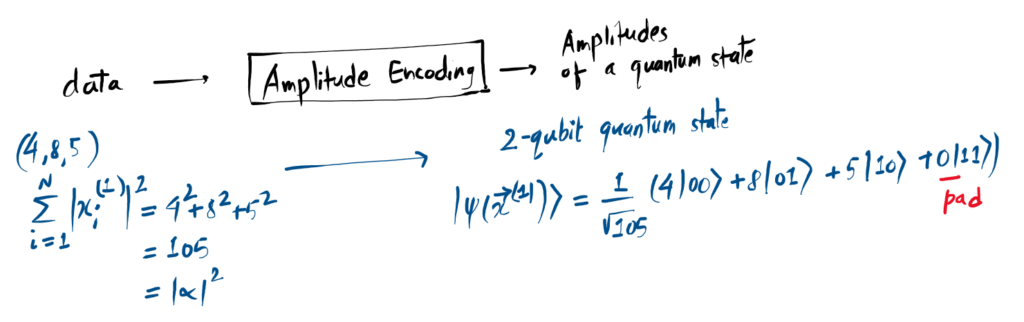
Amplitude Encoding:
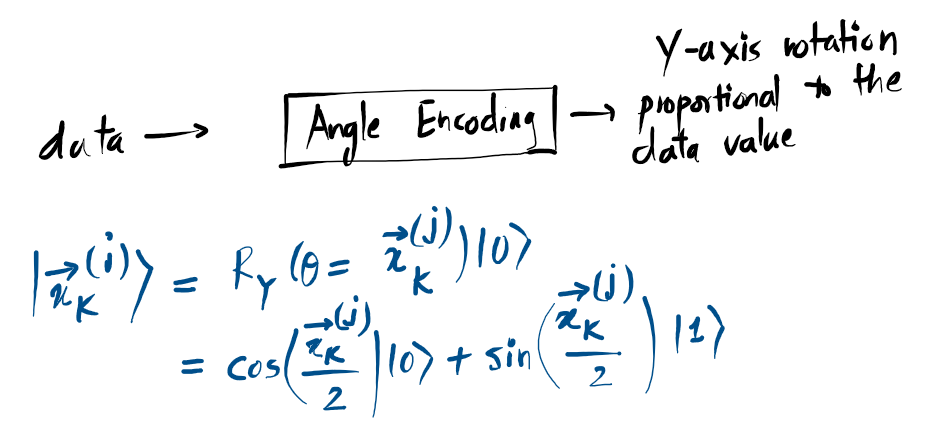
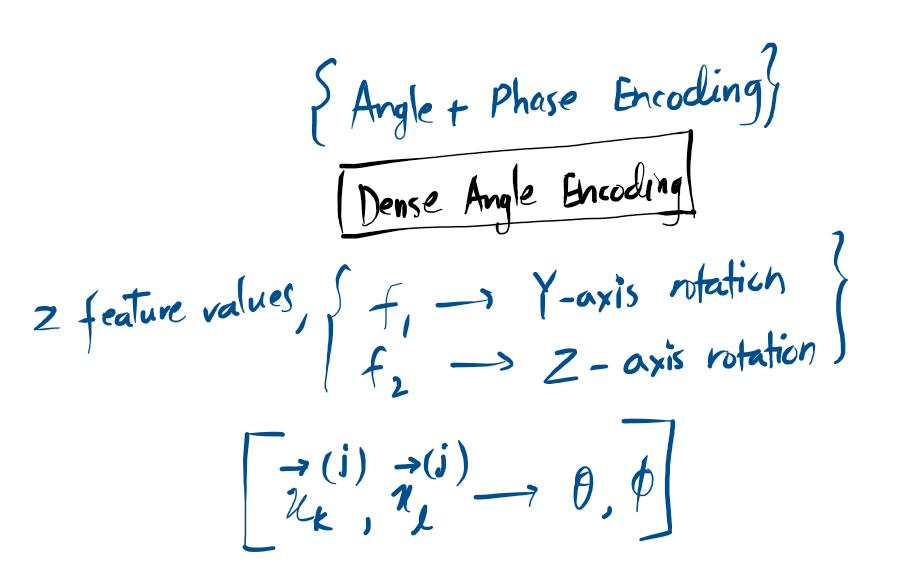
Angle Encoding:
Phase Encoding:
Dense Angle Encoding:
Quantum Data Loading
Quantum Machine Learning starts with a challenge: how do you fit “flat” classical data into a “curved” quantum state? This is Data Encoding.
1. Basis Encoding
This is the most literal method. We treat qubits as bits. If your feature is “1”, we use an X-Gate to flip the qubit vector 180° to point directly down. It maps classical strings to quantum states \(|0\rangle\) and \(|1\rangle\) 1:1.
2. Amplitude Encoding
Think of this as “compressing” information into the probability of a state. We store data in the coefficients of the wavefunction. While space-efficient, it requires complex Initialization circuits that can be quite deep.
3. Angle Encoding
We treat your data value as a rotation angle \((\theta)\). By applying a rotation (like RY), we move the vector along the sphere’s surface. This is perfect for NISQ-era devices because it keeps the circuit extremely short and minimizes noise.
4. Advanced Feature Maps
For complex patterns, we use ZZ and Pauli Feature Maps. These aren’t simple rotations they use Entanglement to link multiple qubits together. This creates a “Quantum Web” of data that allows a model to recognize non-linear relationships that classical computers simply cannot “see”.
References
- [1] “Data encoding | IBM Quantum Learning,” IBM Quantum Learning, 2026. [Online]. Available: https://quantum.cloud.ibm.com/learning/en/courses/quantum-machine-learning/data-encoding