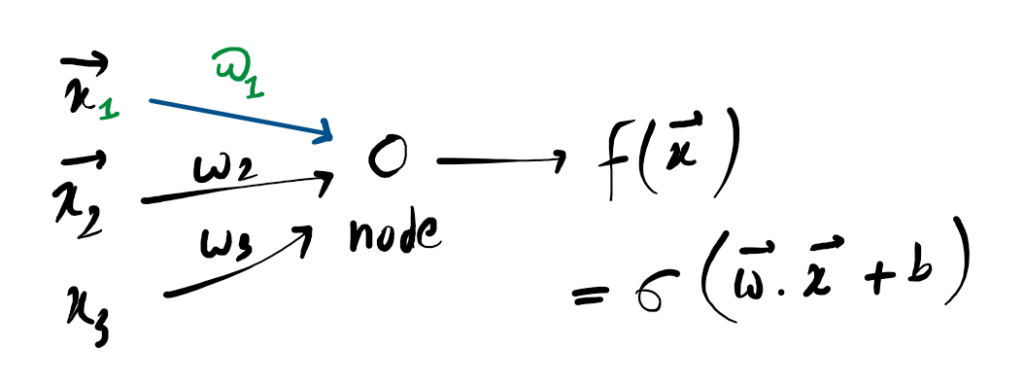To understand Variational Quantum Circuits, we can have analogy with Classical Neural Networks.
NN vs. QNN
Classical Perceptrons (Left) vs. Quantum Gates (Right)
Classical: Data flows through fixed layers of neurons.
Quantum: Data is encoded into qubits and transformed via Rotational Gates.
Non-Linearity: In QNNs, this is typically achieved at the Measurement stage (red icon).
Classical Perceptron:
Building block of Neural Network
It takes input $x$, computes inner product with trainable weight vector $w$ plus some bias $b$.
IT applies non-linear activation function $\sigma$
Perceptron
Input → Weighting → Summation → Activation
How it works: The inputs xn are multiplied by weights wn, summed together with a bias b, and then passed through the activation function σ (Sigma) to produce the final output.
Quantum Perceptron:
Can we implement non-linearity with quantum circuits? Why? Because, quantum circuits only implement unitory operations that are simply linear.
How to introduce non-linearity to quantum circuits?
Use measurements as a source of non-linearity
Others: Quantum Fourier Transform based methods, mid-circuit measurements or dynamic circuits etc.
Quantum Neural Network
A QNN works by encoding data with a unitary layer U, applying weight circuits W, and performing measurement.
Linearity: Data loading and weightings are linear operations.
Non-Linearity: Introduced via the measurement layer.
Hybrid Optimization: Weight circuits have variational parameters requiring classical minimization.
fQNN(x) = ⟨0| U†(X) W† O W U(x) |0⟩
The function is applied across all data loaded by U and may include many layers of weights, differing from classical f(x).
The Data Re-uploading Strategy
Boosting model expressiveness through repetitive encoding
Data Reuploading [S(x)]
The red blocks re-inject the original data into the qubit, allowing the model to “capture” complex features that a single pass would miss.
Universal Classifier
Pérez-Salinas et al. proved that even one qubit can approximate any function if you “re-upload” enough times.
Pérez-Salinas, A., et al. “Data re-uploading for a universal quantum classifier.”, https://quantum-journal.org/papers/q-2020-02-06-226/ Quantum, 2020. Reference via IBM Quantum Learning.
[2]
A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, “Data re-uploading for a universal quantum classifier,” Quantum, vol. 4, p. 226, Feb. 2020.
https://doi.org/10.22331/q-2020-02-06-226