If you want to teach an Artificial Intelligence to play a video game, control a robot, or optimize a trading strategy, you need an environment for it to practice in. Enter Gymnasium (formerly OpenAI Gym), the standard API for single-agent Reinforcement Learning (RL).
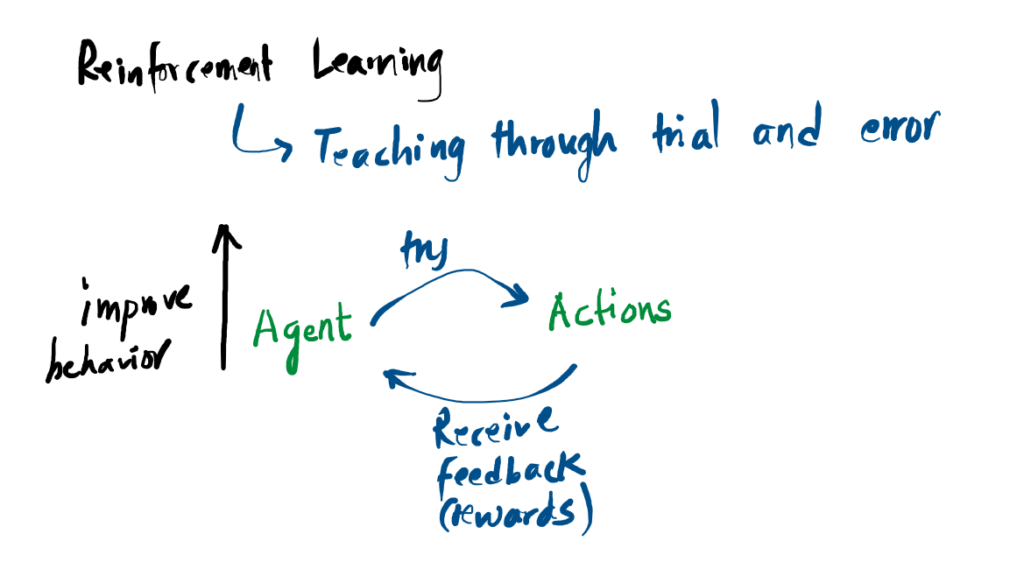
1. The Agent-Environment Loop
Reinforcement learning is fundamentally about trial and error. We don’t program the agent with specific instructions; instead, we drop it into an environment and let it learn from the consequences of its actions.
2. Your First RL Program
Gymnasium provides four primary functions that allow you to build out this continuous loop: make(), reset(), step(), and render(). Here is what a basic implementation looks like using the classic CartPole balancing environment:
import gymnasium as gym
# 1. Initialize the environment
env = gym.make("CartPole-v1", render_mode="human")
# 2. Reset the environment to start the episode
observation, info = env.reset()
episode_over = False
total_reward = 0
while not episode_over:
# 3. Choose a random action (0 = Left, 1 = Right)
action = env.action_space.sample()
# 4. Take the step and observe the results
observation, reward, terminated, truncated, info = env.step(action)
total_reward += reward
# Check if the pole fell (terminated) or hit the time limit (truncated)
episode_over = terminated or truncated
print(f"Episode finished! Total reward: {total_reward}")
env.close()env.action_space.sample(). True machine learning happens when you replace that line with a trained Neural Network policy.
3. Action and Observation Spaces
How does the agent know what it is allowed to do? Every environment comes with predefined boundaries called Spaces.
- Observation Space: What the agent can “see”. For CartPole, this is a
Boxcontaining 4 continuous numbers (position, velocity, angle, angular velocity). For a racing game, it might be a grid of RGB pixels. - Action Space: What the agent can “do”. For CartPole, this is
Discrete(2), representing exactly two available buttons: push left or push right.
Notebook Example:
!pip install gymnasium[classic-control]
!pip install moviepy imageio
Requirement already satisfied: gymnasium[classic-control] in /usr/local/lib/python3.12/dist-packages (1.2.3) Requirement already satisfied: numpy>=1.21.0 in /usr/local/lib/python3.12/dist-packages (from gymnasium[classic-control]) (2.0.2) Requirement already satisfied: cloudpickle>=1.2.0 in /usr/local/lib/python3.12/dist-packages (from gymnasium[classic-control]) (3.1.2) Requirement already satisfied: typing-extensions>=4.3.0 in /usr/local/lib/python3.12/dist-packages (from gymnasium[classic-control]) (4.15.0) Requirement already satisfied: farama-notifications>=0.0.1 in /usr/local/lib/python3.12/dist-packages (from gymnasium[classic-control]) (0.0.4) Requirement already satisfied: pygame>=2.1.3 in /usr/local/lib/python3.12/dist-packages (from gymnasium[classic-control]) (2.6.1) Requirement already satisfied: moviepy in /usr/local/lib/python3.12/dist-packages (1.0.3) Requirement already satisfied: imageio in /usr/local/lib/python3.12/dist-packages (2.37.3) Requirement already satisfied: decorator<5.0,>=4.0.2 in /usr/local/lib/python3.12/dist-packages (from moviepy) (4.4.2) Requirement already satisfied: tqdm<5.0,>=4.11.2 in /usr/local/lib/python3.12/dist-packages (from moviepy) (4.67.3) Requirement already satisfied: requests<3.0,>=2.8.1 in /usr/local/lib/python3.12/dist-packages (from moviepy) (2.32.4) Requirement already satisfied: proglog<=1.0.0 in /usr/local/lib/python3.12/dist-packages (from moviepy) (0.1.12) Requirement already satisfied: numpy>=1.17.3 in /usr/local/lib/python3.12/dist-packages (from moviepy) (2.0.2) Requirement already satisfied: imageio-ffmpeg>=0.2.0 in /usr/local/lib/python3.12/dist-packages (from moviepy) (0.6.0) Requirement already satisfied: pillow>=8.3.2 in /usr/local/lib/python3.12/dist-packages (from imageio) (11.3.0) Requirement already satisfied: charset_normalizer<4,>=2 in /usr/local/lib/python3.12/dist-packages (from requests<3.0,>=2.8.1->moviepy) (3.4.6) Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.12/dist-packages (from requests<3.0,>=2.8.1->moviepy) (3.11) Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.12/dist-packages (from requests<3.0,>=2.8.1->moviepy) (2.5.0) Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.12/dist-packages (from requests<3.0,>=2.8.1->moviepy) (2026.2.25)
import gymnasium as gym
from gymnasium.wrappers import RecordVideo
from IPython.display import Video
import glob
# 1. Initialize with rgb_array so it renders to memory, not a screen
base_env = gym.make("CartPole-v1", render_mode="rgb_array")
# 2. Wrap the environment to automatically record MP4 videos
# We tell it to save in a folder named "video" and record every episode
env = RecordVideo(base_env, video_folder="./video", episode_trigger=lambda x: True)
observation, info = env.reset()
episode_over = False
total_reward = 0
while not episode_over:
action = env.action_space.sample() # Random action
observation, reward, terminated, truncated, info = env.step(action)
total_reward += reward
episode_over = terminated or truncated
print(f"Episode finished! Total reward: {total_reward}")
# 3. Close the environment (this finalizes and saves the MP4 file)
env.close()
# 4. Find the saved MP4 file and display it inside the notebook
video_file = glob.glob("./video/*.mp4")[0] # Grabs the first video in the folder
Video(video_file, embed=True, html_attributes="controls loop autoplay")
/usr/local/lib/python3.12/dist-packages/gymnasium/wrappers/rendering.py:293: UserWarning: WARN: Overwriting existing videos at /content/video folder (try specifying a different `video_folder` for the `RecordVideo` wrapper if this is not desired)
logger.warn(
Episode finished! Total reward: 31.0
import gymnasium as gym
# 1. Initialize the environment
env = gym.make("CartPole-v1", render_mode="human")
# 2. Reset the environment to start the episode
observation, info = env.reset()
episode_over = False
total_reward = 0
while not episode_over:
# 3. Choose a random action (0 = Left, 1 = Right)
action = env.action_space.sample()
# 4. Take the step and observe the results
observation, reward, terminated, truncated, info = env.step(action)
total_reward += reward
# Check if the pole fell (terminated) or hit the time limit (truncated)
episode_over = terminated or truncated
print(f"Episode finished! Total reward: {total_reward}")
env.close()
Episode finished! Total reward: 33.0
Github Link: https://github.com/computingnotes/Gymnasium_RefinforcementLearning
Reference
[1] “Gymnasium Documentation,” Farama.org, 2025. https://gymnasium.farama.org/introduction/basic_usage/