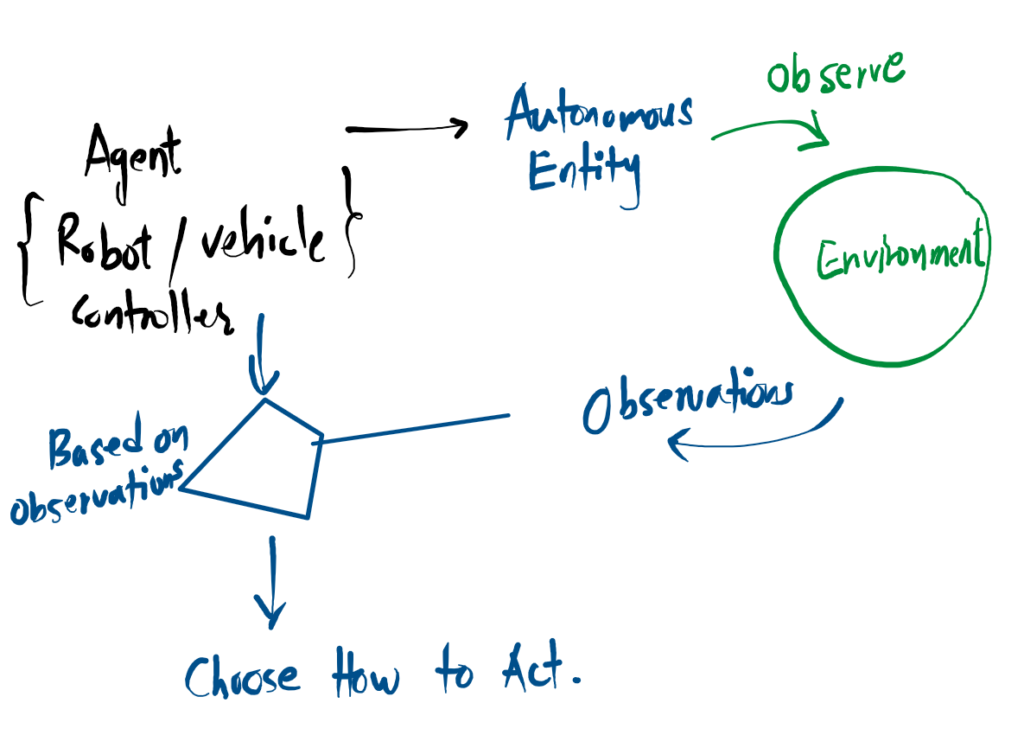
What is an Agent?
The three core characteristics of an autonomous system.
Autonomous Entity
It operates independently as a self-directed entity, without requiring constant human intervention or manual control.
Observes Environment
It continuously monitors its surroundings, gathering real-time state data and information about the world around it.
Chooses How to Act
Based entirely on those observations, it makes independent decisions and calculates the optimal action to take.
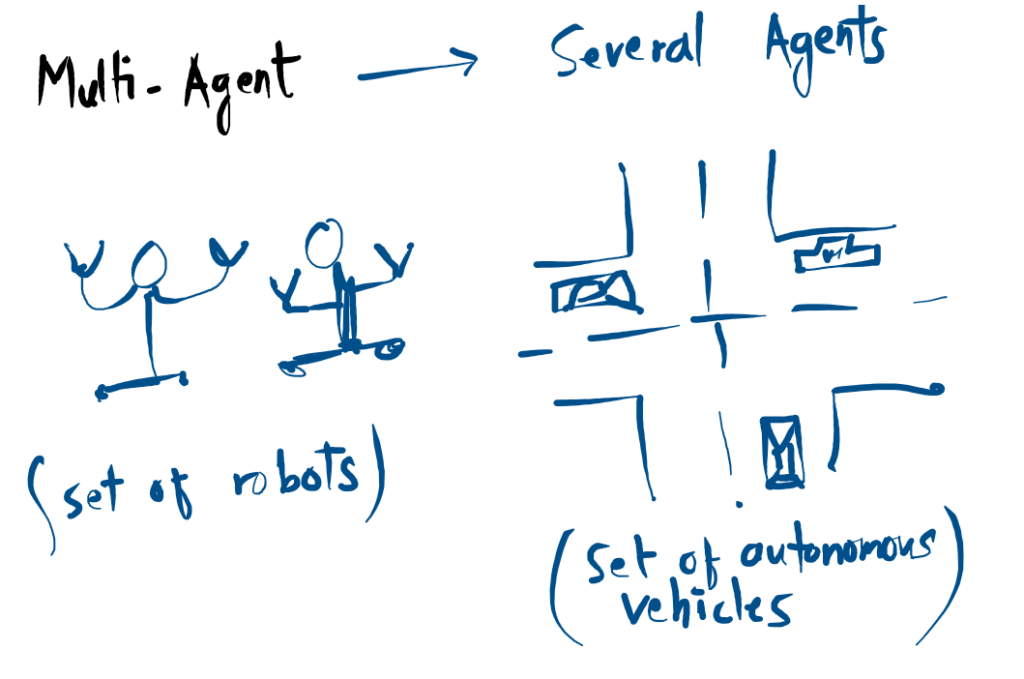
Multi-Agent Systems (MAS)
A Multi-Agent System is more than just a collection of robots; it is a collaborative network where several autonomous entities share a common environment to achieve complex goals.
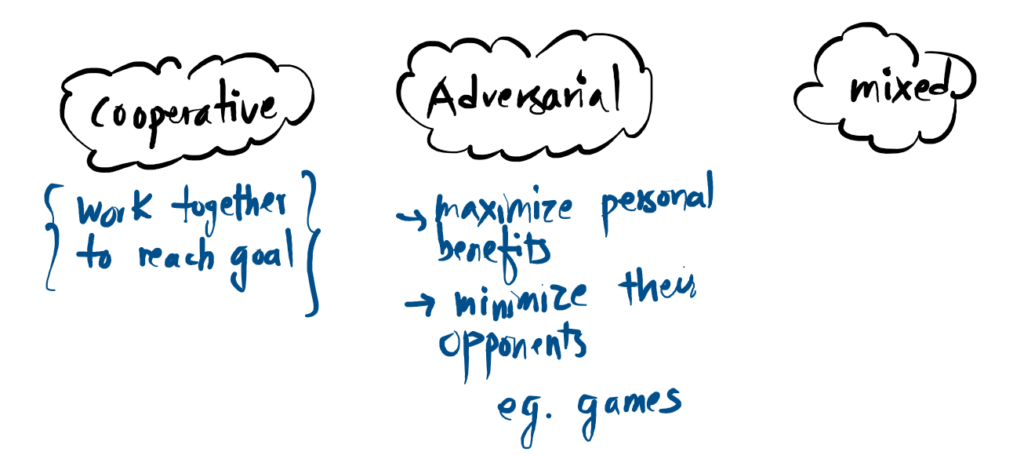
Agent Interaction Dynamics
How multiple autonomous entities behave toward one another in a shared environment.
Cooperative
Agents work together as a unified team to reach a common goal. Success is shared, and individual actions are optimized to maximize the total group reward.
Adversarial
A zero-sum environment where agents compete. Each entity focuses on maximizing its own personal benefit while simultaneously working to minimize the performance of opponents.
Mixed
The most complex scenario where both cooperation and competition exist. Agents may form temporary alliances or compete for limited resources while working toward a broader objective.
Designing the Agent’s Logic
How do we decide what an agent does? There are two primary schools of thought.
Direct Encoding
Humans determine the behavior ahead of time. We impart our knowledge directly into the agent using explicit code (e.g., “If red light, then stop”). This is predictable and reliable but doesn’t scale well to complex edge cases.
Self-Learning
Agents learn behaviors on their own through trial and error. They interact with the environment to maximize a reward signal. This allows for the discovery of highly efficient, complex strategies that humans might never think of.
| Feature | Encoded Behaviors | Learned Behaviors |
|---|---|---|
| Logic Source | Human Programmer | Reward & Interaction |
| Predictability | High (Deterministic) | Lower (Evolving) |
| Adaptability | Low (Manual Updates) | High (Self-adjusting) |
| Best Use Case | Simple, Safety-Critical | Complex, Fluid Tasks |

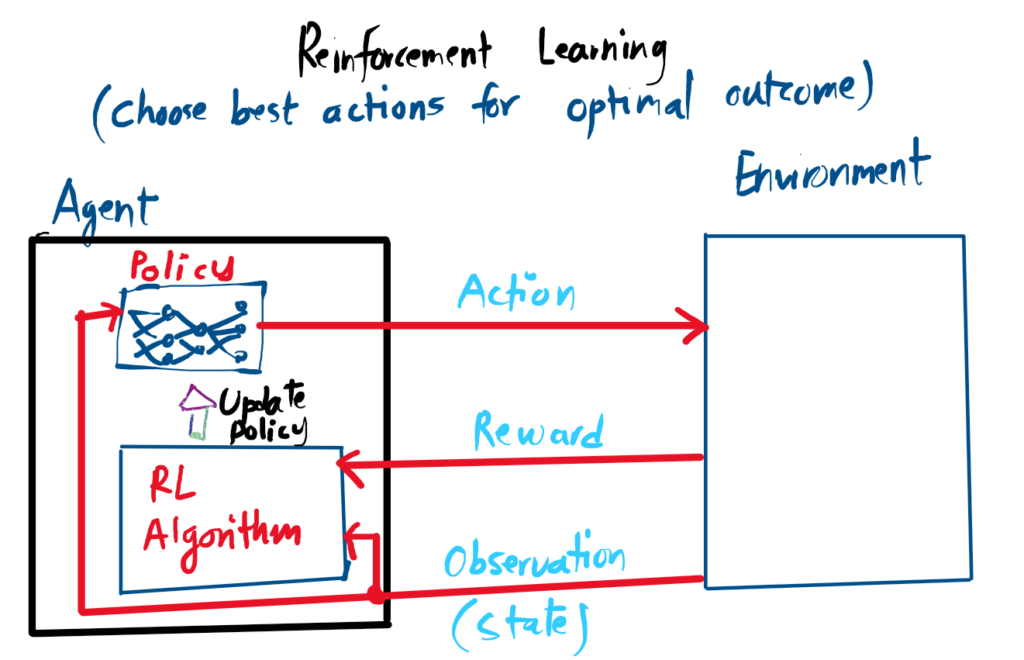
Agent exists within an environment.
Agent observes environment States.
Policy determines the next Action.
Action updates the environment state.
Rewards granted (may be sparse/delayed).
Algorithm updates policy to maximize total reward.
Reinforcement Learning
- Agent exists within an environment
- Agent abserves the states of the enviroment
- Agent policy decides which action to take
- Action affects the environment state
- Reward may be granted based on the new state and action pair (Reward can be sparse, only receive after number of sequential actions)
- RL algorithm update the agent policy overtime to maximize the reward.
With Multi-Agent RL, we have multiple agent interacting with the environment.
MARL approches
- Decentralized: Each agent trained independently to other agents; no information shared between agents; Simplified design with no communication; Not aware of other agents actions or what they have done.
- Centralized: Higher level of collection of shared information/experiences; learning policy from all experiences and sharing
Decentralized
- Independent Training: Each agent learns entirely on its own.
- No Communication: Zero information sharing between entities.
- Simplified Design: No complex hardware for data transfer.
- Unaware: Agents are blind to the actions and history of others.
Centralized
- Data Collection: Higher-level gathering of all agent experiences.
- Shared Wisdom: A single policy learns from the total collective data.
- Coordinated Learning: All agents benefit from each other’s successes.
- Global View: Decisions are made using the full context of the environment.
References
Available at bartdeschutter.org/publications/…