Q Learning algorithm is:
- Off Policy Reinforcement Learning Method
- For Environments with Discrete Action Function
The figure below shows how a Q-learning agent trains on Q-Value function critic in order to estimate the optimal policy value. It follows epsilon greedy policy based on the value that is determined by the critic.
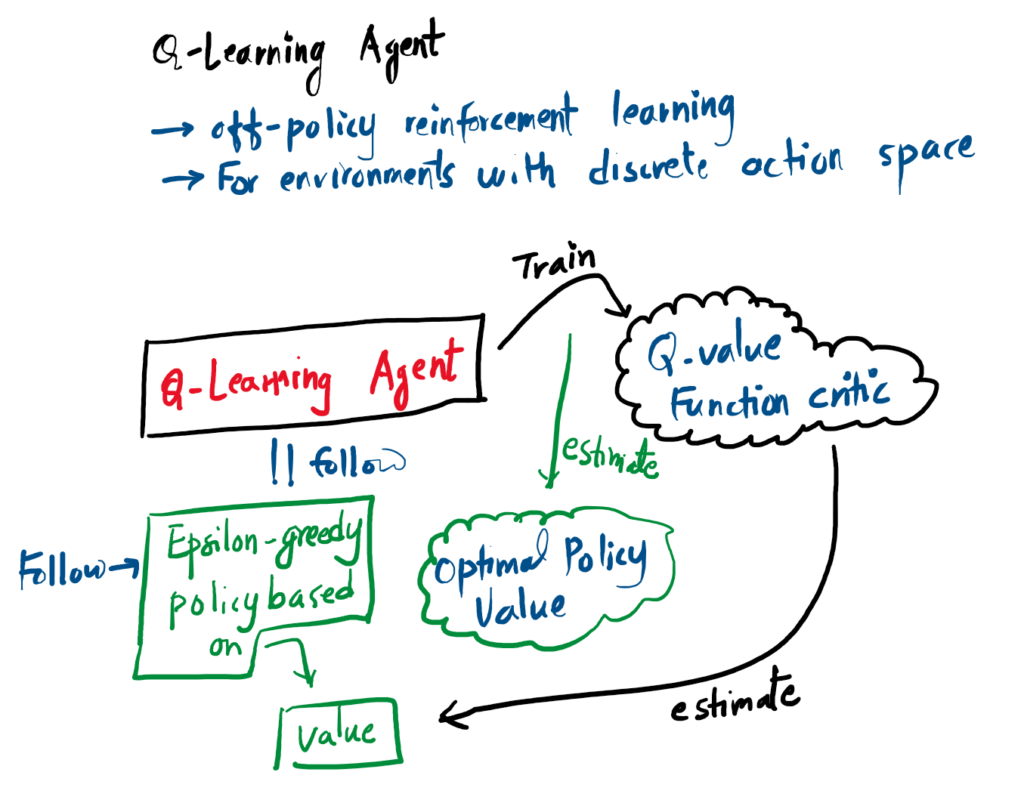
The Internal Flow of a Q-Learning Agent
Unlike basic algorithms, a Q-Learning agent splits its logic. The Critic learns the exact value of the environment over time, and the Policy uses those values to decide whether to explore or exploit.
Picks Best Action OR Explores Randomly
Estimates optimal policy value: Q(S,A)
The Epsilon-Greedy Exploration Strategy
During training, the agent uses epsilon-greedy exploration to navigate the action space. At each step, a random action is selected with a probability of ε (exploration). Otherwise, the agent selects the action with the highest estimated value from the action-value function with a probability of 1-ε (exploitation).
The Critic: Estimating the Future
To figure out how valuable a specific policy is, the Q-Learning agent relies on a Critic. Think of the Critic as a function approximator, a mathematical engine that implements the parameterized action-value function: $Q(S, A; \phi)$.
When you feed the Critic a specific Observation ($S$) and an Action ($A$), it looks at its internal parameters ($\phi$) and outputs an estimate of the expected discounted cumulative long-term reward. In simpler terms: it predicts your final score if you take that action.
+
Action (A)
(Long-term Reward)
Training Phase vs. Deployment: During the learning process, the agent constantly calculates the error between what the Critic predicted and what actually happened. It uses this error to “tune” the parameters ($\phi$). Once training is complete, these parameters are locked in, and the agent simply uses the Critic’s evaluations to navigate the environment.
Table-Based Critics
In simple environments with discrete states and actions, the parameters $\phi$ are literally just the actual cells in a lookup table. The agent updates the numbers in the grid.
Neural Network Critics (DQN)
In complex environments (like processing video game pixels), a table is too large. Here, the parameters $\phi$ represent the weights and biases of a deep neural network.
The Q-Learning Agent
Q-learning is one of the most foundational algorithms in Reinforcement Learning. It is a value-based, off-policy method designed specifically for environments with discrete action spaces (like pressing up, down, left, or right).
Unlike policy-based algorithms, a Q-learning agent does not try to explicitly learn a “rulebook” or an Actor. Instead, it relies entirely on a Critic. The Critic’s job is to map out the environment and estimate the exact long-term value of every possible action in every possible state. Once the Critic is trained, the agent’s strategy is incredibly simple: look at the Critic’s evaluations and aggressively choose the action with the highest expected reward.
Implementation in MATLAB’s Reinforcement Learning Toolbox™
If you are building this agent using the Deep Reinforcement Learning (DRL) Toolbox, here is how the theory translates to code:
- The Agent: You will instantiate the agent using the
rlQAgentobject. - The Critic: You must create a Q-value function critic $Q(S,A)$ using either
rlQValueFunctionorrlVectorQValueFunction. - Constraints: Your environment must have a discrete action space.
The Training Algorithm & Math
How does the Critic actually learn these values? The agent learns by interacting with the environment, observing the outcomes, and continually updating its internal Critic parameters ($\phi$) using a 5-step mathematical loop based on the Bellman Equation:
-
Observation & Exploration: The agent observes the current state $S$. To ensure it discovers new strategies, it uses $\epsilon$-greedy exploration: it selects a completely random action with a small probability ($\epsilon$). Otherwise, it exploits its current knowledge by selecting the action that maximizes the current Q-value:
$$A = \arg\max_{A’} Q(S, A’; \phi)$$
- Execution: The agent executes action $A$ in the environment. It then observes the immediate reward $R$ and the resulting next state $S’$.
-
Calculate the Target: The agent calculates the “value function target” ($y$) essentially, what it should have predicted. If $S’$ is the end of the game, $y = R$. Otherwise, it factors in the discount rate ($\gamma$) and the value of the best possible future move:
$$y = R + \gamma \max_{A’} Q(S’, A’; \phi)$$
-
Calculate the Error: The agent finds the difference ($\Delta Q$) between the calculated target and what the Critic originally predicted:
$$\Delta Q = y – Q(S, A; \phi)$$
-
Update the Critic: Finally, it updates its parameters using a learning rate ($\alpha$). For a simple table-based critic, the update is direct:
$$Q(S,A) \leftarrow Q(S,A) + \alpha \cdot \Delta Q$$
If you are using deep reinforcement learning (where the Critic is a neural network), the agent updates its network weights ($\phi$) using gradient descent, aiming to minimize the square of this error.

References
[1] “Q-Learning Agent – MATLAB & Simulink,” Mathworks.com, 2018. https://au.mathworks.com/help/reinforcement-learning/ug/q-learning-agents.html